
Build Fast & Scalable Services in the Cloud Pt 2: Application Services
By Aleksey Staroverov, Development Manager of 2C2P
Scalability is crucial to the life of any application service. If an application service is not built for scalability, it will fail to handle increased users and workload, and inevitably affect the performance of a business and the end-user experience.
In this article, we will explain more about the typical issues encountered when building scalable application services. This includes the considerations when building a scalable application service, the overall experience of your users, page loading times, the time required to make changes in the code, and even the cost of updating the entire application.
If you haven’t, read part 1 here to learn more about building a scalable infrastructure in the Cloud for financial services.
Scalable Application Services
Application services are part of any system where our code runs. This is related to the business logic of a system.
Application services can be deployed to servers at data centres for traditional systems, typically connected to a single database server. A single database server would however mean that the system is not highly available as there is a single point of failure, and is also often only vertically scalable.
Notwithstanding, building a highly scalable and highly available system also presents some challenges.
There are some considerations related to the distributed nature when the application is developed. In our case, we faced the following issues:
State management
Scalable data storage
Caching
Cache invalidation
Synchronisation between service instances
Single point of failure
Bottlenecks
Before deep-diving into the various issues, note that each distributed system must consider the CAP (Consistency, Availability, Partitioning) theorem. This means we cannot have a highly available system tolerant to partition failures coupled with solid consistency.
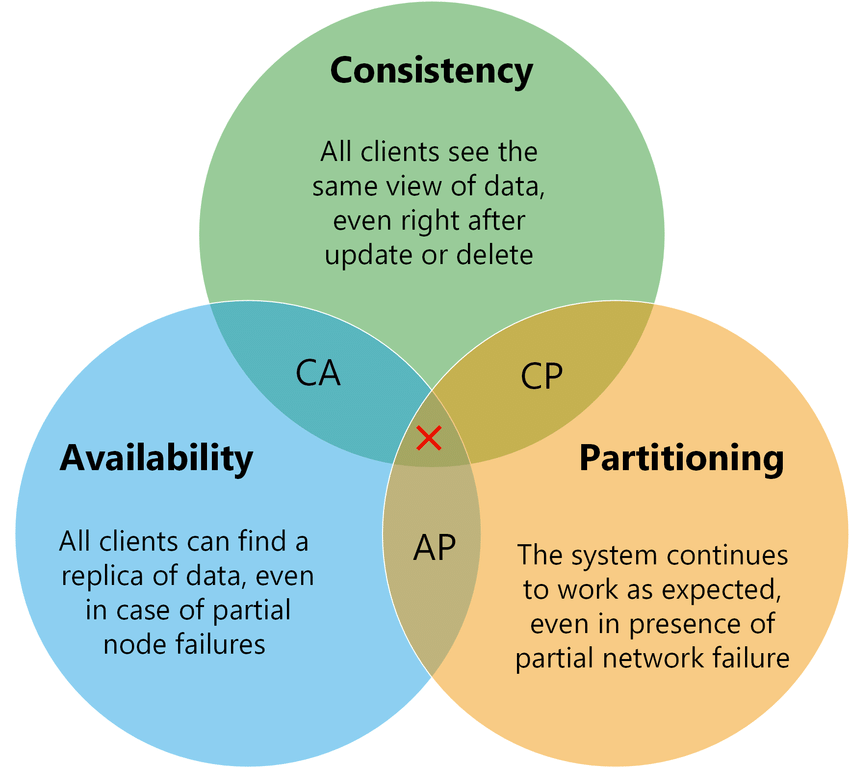
The CAP theorem.
The typical compromise here is by choosing the Eventual Consistency with Availability and Partitioning. That means that our data will eventually be consistent after some time.
Message Queueing (Simple Queue Service)
Message queuing is typically used to perform long-running operations on separate server instances to offload client-facing application services and minimize latency, and maximize throughput for them.
Often, message queuing is the core of the system and is used as the primary data source. In this instance, it would be suitable to use Apache Kafka, a famous distributed event streaming platform, which persists events on a hard drive, and is able to replay and restore them. Another usage for message queues is asynchronous notification about events in the system or integration with other systems.
Simple Queue Service (SQS) is a fully managed message queuing service that connects different system components with loose coupling.
We used SQS for a few different cases:
1. All our writes and updates to the database are considered slow operations and are sent to SQS before another service handles them. SQS guarantees at least one delivery, which means that our consuming application service needs to handle duplicate messages. If the database is unavailable, our application services will continue to work.
2. SQS integrates with other systems or performs an operation that does not require waiting time to receive response. For example, when we send an email or a short message service (SMS), it is more important to respond to the customer rather than waiting for the result. If a user doesn’t receive an SMS, they can request a response again. This process improves the user experience.
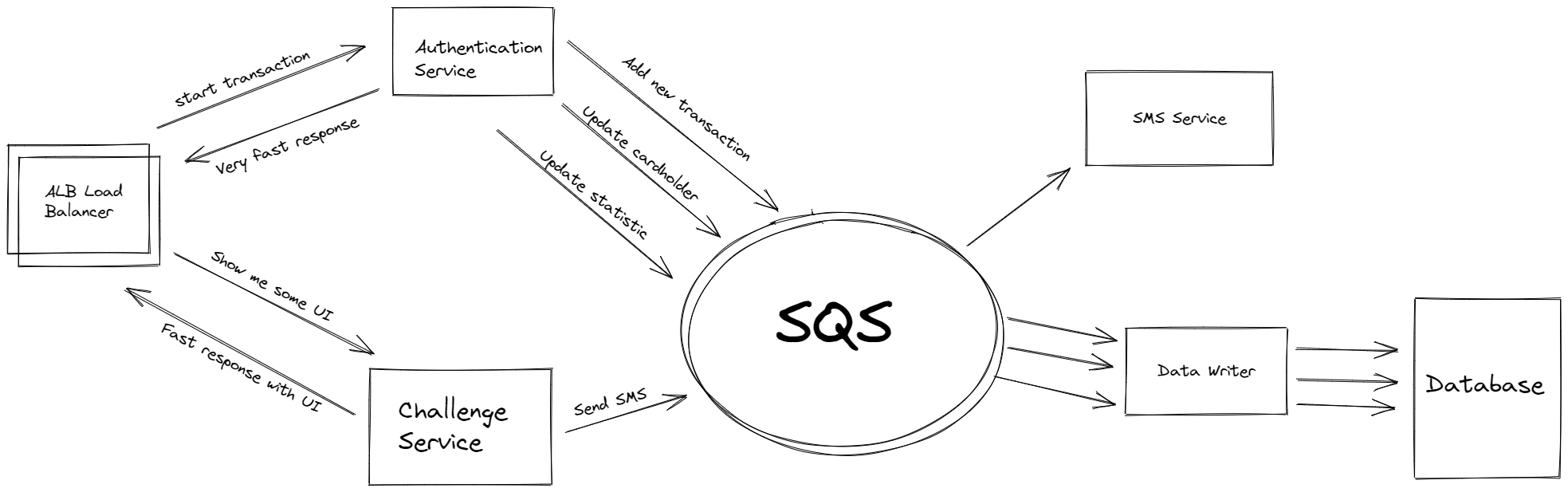
Application services send requests for long-running operations to SQS, which are handled on other services asynchronously.
Using SQS, you can send, store, and receive messages between software components at any volume without losing messages or requiring other services to be available. SQS eliminates the complexity that comes with managing and operating message-oriented middleware and dramatically reduces manual monitoring.
Caching (Redis)
Redis, also known as Remote Dictionary Server, is a fast, open-source, key-value data store. It is used to offload the primary storage of data (typically relational database) and improve performance.
Depending on the deployment mode, Redis is a distributed and highly available system. For high availability systems, master/slave nodes can be used. On the other hand, for distributing loads, Redis can be deployed in Cluster mode.
For 2C2P’s ACS, we use AWS Elasticache service, which provides managed Redis service. It is straightforward to maintain and monitor Redis. In addition, we can add or remove nodes (servers) from the AWS console or Command Line Interface (CLI) and automate it with CloudWatch events.
ACS stores most of our critical transaction data in the Redis or memory, allowing us to offload a database of 99% queries. Suppose queries to the database are not avoidable because there are gigabytes of data, and it is challenging to predict which part is being used. In that case, we can use database replicas from AWS Aurora.
As AWS uses load balancers to monitor the availability of database nodes, our system will remain available even if one of the read replicas is down. The system will also stay available if some nodes of Redis are down as slave nodes will automatically be promoted to master.
Apart from storing hot data in the cache, we use Redis to store the state of our transactions. The nature of our ACS solution requires us to maintain the current state of transactions and update it based on incoming requests. As our writes are asynchronous, some data in the database are only eventually consistent as they might not be updated instantly. Therefore, we need to maintain the current state of the transaction in a separate cache.
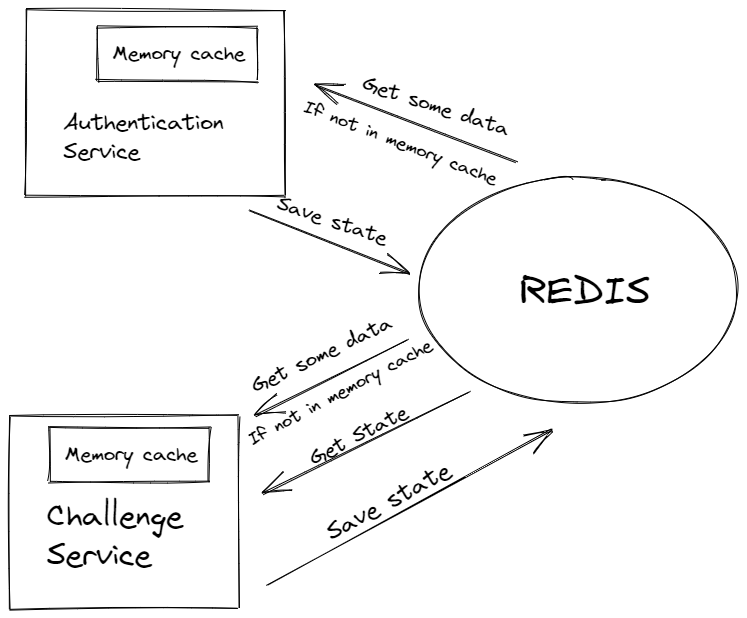
Application services use Redis as a cache and state provider.
Redis is perfect for financial services as it delivers sub-millisecond response times, enabling millions of requests per second for real-time applications. All Redis data resides in memory, which allows low latency and high throughput data access.
Publisher/Subscriber for Cache Invalidation (Redis)
Another typical issue related to the distributed nature of scalable services in the cloud is cache invalidation.
For our ACS solution, we have a different system. For example, when an admin service occurs, some data such as styling or texts for users, system parameters, and information stored in the server’s memory cache and Redis cache will be updated. All our services need to be notified immediately to clear the memory cache and receive the updated data when this update occurs.
A solution would be to introduce an endpoint in each application service and call it for every update. However, this is a tedious process as a list of instances needs to be managed for each service and requires additional coding.
An alternative is to use the publish/subscribe model. In this model, we typically have many subscribers and publishers. Some services manage subscribers' connections - each time a publisher sends a notification, all the subscribers receive it.
For our ACS solution, we use the Redis Publisher/Subscriber to perform these notifications. All our application services subscribe to “channels”. Therefore, when other services have an update, it sends notifications to the channel and all subscribed services.
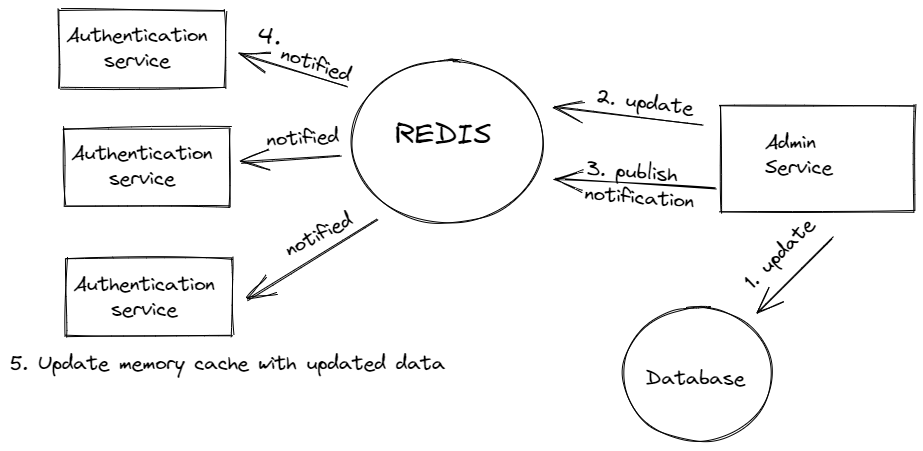
How Redis Publisher/Subscriber works.
Here is how it works:
1. Admin service updates data in the database
2. Admin service updates data in Redis.
3. Admin service sends a notification to Redis.
4. Application services receive a notification about updates.
5. Application services clear the memory cache, and with the subsequent request, it gets an updated version from Redis and saves the new version in the memory cache.
Distributed Locks (Redis)
We often use database servers and database transactions with different isolation levels to synchronise concurrent operations for traditional solutions. In distributed systems, database transactions can be used; however, it is not widely used as a cheaper and faster solution is needed.
Distributed locks are used to guarantee that selected data is handled consequently and not simultaneously. For instance, a user who only has $100 in his bank account makes two $100 transactions simultaneously. Both transactions will be processed without distributed locks, and the user will have -$100 in his bank account. As a result, distributed locks are one of the most widely adopted features in distributed systems to avoid logical failures.
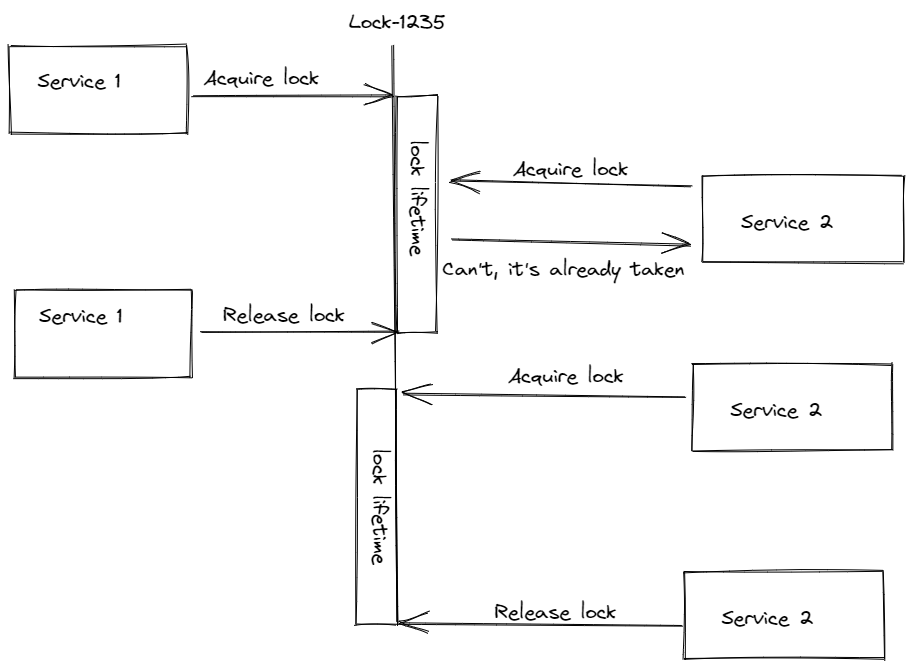
How distributed locks are used across multiple services.
For our ACS solution, we use Redis to implement distributed locking. Nonetheless, there are a few considerations to keep in mind when working with distributed locks:
1. Don’t keep it locked forever. If a service acquires a lock but the system is down, you will need to release the lock within a specific time frame; otherwise, the data will become unavailable.
2. This is related to the point above. You will need to know how long an operation takes when the service is locked. If the operation takes longer than the timeout, the lock will be released too soon. Therefore, you will need to either extend the lock or ensure operations are completed before the timeout.
3. Ensure only the system that acquires the lock can release it. Otherwise, the locks become pointless.
Other Bottlenecks (Cloud HSM)
A bottleneck occurs where the system's performance is restricted due to a single or a limited number of components or resources. Bottlenecks can arise in all parts of a system - proxy server, NAT server, or external services – required for a system to function.
In traditional systems, a typical bottleneck is caused by the database server as it is shared between multiple components. In a situation like this, the system’s performance cannot be improved even if application services are scaled as the database has reached its limit.
In some cases, there are workarounds such as using multiple proxy servers with load balancers instead of one and using the AWS NAT (Network Address Translation) Gateway service instead of the NAT server. However, there may be cases where there are no workarounds.
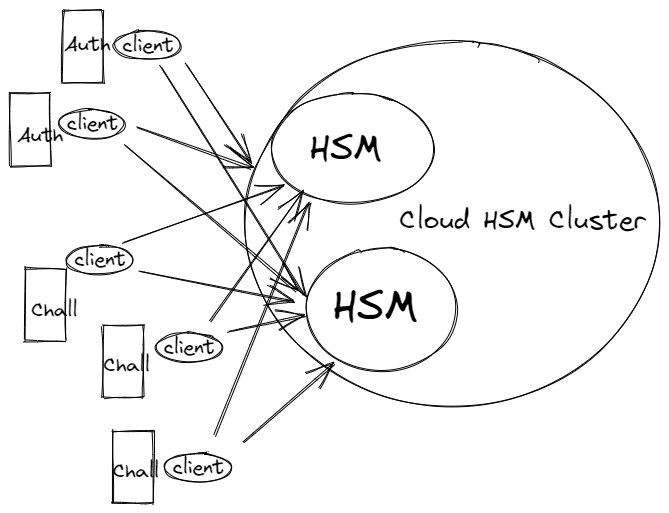
How CloudHSM helps to conquer bottlenecks.
For our ACS solution, the main bottleneck was the Hardware Security Module (HSM), a single box stored in a secured location. When every request is sent to this box, the entire system cannot maximise its performance as the HSM should.
Luckily, we found a workaround for this - Cloud Hardware Security Module (HSM) was the perfect solution. It is a worthy investment for financial services as it mitigates this bottleneck.
The key benefits of Cloud HSM are its scalability and maximum security, ensuring companies have more flexibility and agility when it comes to performance and capabilities.
Conclusion
Thus far, we have embarked on a long journey of continuous improvements and adjustments in order to achieve our goal of building an agile, fast and reliable system for our customers.
So, what does this mean for the customer?
According to our latest load test results, our ACS solution easily handles four times more TPS (transactions per second) than our previous load test benchmark figure in a single AWS region, and can scale to a much higher number where necessary.
Each transaction typically consists of three to four subsequent requests, which makes this feat even more incredible. As for latency, our ACS solution is able to complete 90% of requests in less than 500 milliseconds and complete 95% of requests in less than 1 second.
If we consider that ACS implements plenty of sophisticated business logic and cryptographic operations, this is a great result, and our clients confirm it by choosing us as their payment provider.
The Future of Financial Services is in the Cloud
At 2C2P, our mission is to continuously innovate and build a secure, durable platform that powers global businesses to navigate the complexity of payments.
We partner with Amazon Web Services (AWS) to continually build our Access Control Server (ACS), a scalable infrastructure for our systems with high-performing applications. This innovative solution helps our global clients sell to customers in emerging markets efficiently and it enables companies in those markets to sell to global customers effectively.
Enjoy lesser downtime, secure transactions, and better payment experiences for your customers. Leverage 2C2P’s award-winning secure payment platform. Chat with our friendly team today.

